

Annunciato pochi giorni fa, GPT-4 è già tra noi, giusto pochi mesi dopo l’esplosione di ChatGPT e la public release di GPT-3. Già disponibile in ChatGPT Plus, vediamo le differenze rispetto al precedessore in termini di miglioramenti, prestazioni, funzionalità, metodi di apprendimento e possibilità da esplorare.
Non capire che il lancio di ChatGPT è stato un anno zero per l’Intelligenza Artificiale vuol dire non avere gli occhi sulla realtà. Allo stesso modo, non aspettarsi che questi saranno mesi e anni densissimi di sviluppi molto rapidi, perché la rivoluzione dell’AI sta esplodendo proprio ora, è da miopi. E questo è l’anno in cui tale rivoluzione si consoliderà e, con un grande forse, possiamo timidamente cominciare a parlare per davvero di “intelligenza”, nonostante la complessità che questo concetto oscuro si porta dietro nelle scienze cognitive e nella Cognitive AI.
Ma cos’è GPT-4, il Large Language Model tanto vociferato nei mesi scorsi e già uscito ieri, 14 marzo 2023, a pochissimi mesi di distanza dalla release di GPT-3 a luglio 2022 e di ChatGPT (basato su GPT-3.5) a dicembre 2022? Ecco quello che sappiamo, tra caratteristiche, miglioramenti, accuratezza, prestazioni, funzionalità, metodi di apprendimento e possibilità da esplorare.
Cosa cambia e cosa resta da GPT-3 e ChatGPT
Dopo uno speciale di 4 articoli su GPT-3 e ChatGPT è inutile ribadirlo, ma GPT-4 (quarta generazione della serie di language model GPT-n di OpenAI) è basato sull’architettura Transformer (come suggerisce nuovamente il nome stesso: Generative Pre-trained Transformer 4), quindi tutto ciò che è stato detto nell’analisi di GPT-3 resta invariato.
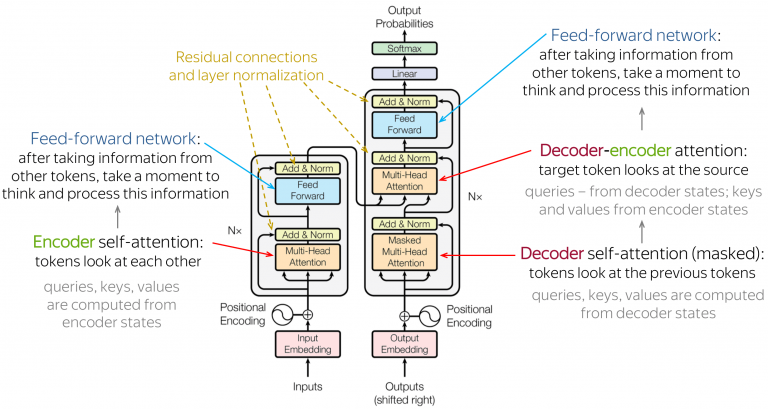
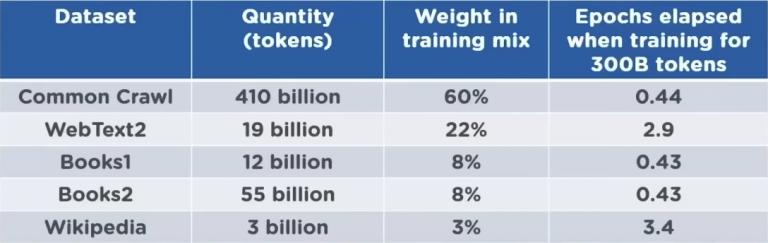
Per fare una brutale sintesi, Transformer è un’architettura neurale basata sul deep learning (costruita da Google e su cui si basa anche BERT) che manipola, comprende, genera testo in linguaggio naturale (siamo quindi nell’ambito del NLP, Natural Language Processing) rendendo il linguaggio un fatto statistico: sulla base di un massiccio training (che, come per ogni AI, continua anche durante l’utilizzo pubblico) basato sull’intero scibile presente nel web (Wikipedia inglese, dataset come WebText2, Books 1 e 2 e Common Crawl, quindi sia dati pubblici che “dati concessi in licenza da fornitori di terze parti”), GPT-3, GPT-3.5 e GPT-4 possono padroneggiare il linguaggio umano a livelli altissimi, creando delle dipendenze statistiche tra i token (in NLP, le unità semantiche in cui si scompone un elaborato linguistico; in questo caso le parole) e prevedendo, di volta in volta, il token che ha la maggiore probabilità di venire dopo il precedente. Una parola per volta, ecco che i modelli GPT riescono a elaborare testi spesso inconfondibili da quelli umani, non fosse per una certa impostazione e formalità di fondo che fanno tanto copywriting basico.
Purtroppo, non connettendosi a Internet, anche GPT-4 ha una conoscenza limitata dai dati di crawling, il cui cut off è fermo al 2021 come per ChatGPT e GPT-3 da risolvere.
Nei mesi scorsi, in tanti ci siamo lamentati di come ChatGPT inizialmente non sapesse svolgere semplici operazioni matematiche (poi è stato implementato il calcolo con le successive patch) né risolvesse semplici quesiti logico-linguistici che si somministrano con successo già ai bambini. Nel tempo, però, abbiamo visto anche un netto miglioramento di queste e tante altre prestazioni, perché l’utilizzo massiccio degli utenti ha chiaramente incrementato l’apprendimento di ChatGPT e contribuito al suo training: ricordiamo che un’AI è tale perché è un software che auto-apprende, sia dal pre-training, sia dall’utilizzo post-release, migliorando nel tempo le proprie prestazioni sui medesimi task.
Multimodale è meglio
Anche GPT-4, come i predecessori, è un misto di supervised, unsupervised e reinforcement learning, ma con una specificità derivante proprio da questa premessa: prima di essere testato su vari benchmark professionali e accademici, il fine tuning è stato effettuato utilizzando il reinforcement learning from human feedback, che addestra il sistema di ricompense direttamente dal feedback del revisore umano e lo utilizza come funzione di ricompensa per ottimizzare l’efficienza di un agente utilizzando il rinforzo stesso. Sebbene meno capace degli umani in molti scenari del mondo reale, esibisce prestazioni a livello umano su vari benchmark professionali e accademici, compresi quelli sul commonsense reasoning (di cui si è parlato anche qui): OpenAI ha infatti coinvolto oltre 50 esperti di vari settori per testare il modello, fornendo feedback che sono andati ad aumentare la robustezza generale del sistema.
Non solo: nell’ambito della human-computer interaction, le modalità sono gli specifici canali indipendenti di input/output sensoriali tra macchina e umano, sicché un sistema è unimodale se implementa una sola modalità e multimodale se ne implementa molte. Ebbene, GPT-4 rappresenta un obiettivo a lungo paventato dagli addetti ai lavori, perché non è semplicemente un large language model (una rete neurale NLP di grandi dimensioni, con numerosi parametri e almeno miliardi di pesi), ma un large multimodal model. Questo è reso possibile dall’expertise che OpenAI ha guadagnato con lo sviluppo e il successo di DALL-E e DALL-E 2 (un po’ le controparti artistiche e visuali dei GPT), ma soprattutto grazie al multimodal learning, un metodo di apprendimento che modella la combinazione di diverse modalità di dati, come testo (tendenzialmente rappresentato da vettori di conteggio di parole discrete) e dati di imaging (rappresentati da intensità di pixel e annotation tag).
E infatti GPT-4 integra anche un visual model (forse uno degli upgrade più attesi dagli utenti e dagli investitori) ed è in grado di ricevere compiti di visione e/o linguaggio, accettando in input sia immagini (o altri elementi grafici come diagrammi e schermate) che testo, pur restituendo in output solo testo (didascalie, classificazioni e analisi, anche molto lunghe e dettagliate): “Ad esempio – scrive Il Sole 24 Ore – in una prova un utente gli ha dato un’immagine dell’interno del frigorifero, chiedendogli quali ricette si possono fare con quei cibi che si vedono. E il bot ha fornito alcune ricette, corrette, con quegli ingredienti“. Oppure ancora, nell’evento di lancio un esempio eclatante è stata la foto del taccuino dello sviluppatore su una pagina che abbozzava molto embrionalmente una landing page interamente disegnata e scritta a mano; alla richiesta dello sviluppatore di realizzare un sito basato sull’abbozzo, non solo GPT-4 ha riconosciuto testo e tratti, ma li ha perfettamente riprodotti in HTML e CSS.
Dal momento che le modalità hanno proprietà statistiche fondamentalmente diverse (e le modalità testuali e visuali in maggior misura), combinarle è tutt’altro che banale e richiede algoritmi e strategie di modellazione specializzati. Per il momento, comunque, si tratta di una multimodalità “limitata” rispetto a quanto emerso in precedenza, in cui si faceva riferimento anche a possibili risposte in forma di immagini e video (con tutti i dubbi connessi al copyright che la scelta avrebbe sollevato).

Riallacciandoci ai miglioramenti già notati dalle varie patch di ChatGPT riguardo le operazioni matematiche e logiche, in GPT-4 assistiamo a un salto notevole, dato che nell’evento di lancio ufficiale abbiamo appurato la sua capacità di svolgere operazioni contabili anche piuttosto complesse per calcolare e amministrare la fiscalità, le dichiarazioni dei redditi o altro. Ma gli affinamenti riguardano anche altri ambiti, come la programmazione e la consulenza: noto è il caso di Anil Gehi, professore associato di medicina e cardiologo presso l’Università del North Carolina a Chapel Hill, che ha illustrato al chatbot (in termini tecnici e complessi) la storia medica di un paziente che aveva visitato il giorno prima, comprese le complicazioni post-ricovero ospedaliero. Alla richiesta di Gehi su come avrebbe dovuto trattare il paziente, il chatbot gli ha dato la risposta giusta: magari un caso, ma già meglio di GPT-3.
Ancora, GPT-4 è in grado di gestire oltre 25.000 parole di testo, il che consente casi d’uso come la creazione di contenuti di lunga durata, conversazioni estese e ricerca e analisi di documenti. Rispetto a GPT-3 e 3.5 (che avevano un contesto lungo 2048 token), GPT-4 ha infatti una lunghezza del contesto di ben 8.192 token, ma, stando alla presentazione di ieri, OpenAI fornirà un accesso limitato addirittura alla versione da 32.768-long-context. Dimensioni del genere permetteranno finalmente di lavorare con interi libri, pagine web e documenti accademici completi, senza la necessità di dividere il testo come accaduto finora: per fare un esempio, GPT-4 è riuscito anche a fare una sintesi corretta di un lungo articolo del New York Times. Mentre ChatGPT avrebbe fallitto una prova del genere, GPT-4 risulta molto migliorato, pur continuando a commettere inevitabili errori (non esisterà mai un’AI perfetta, men che meno adesso che stiamo solo cominciando a ingranare).
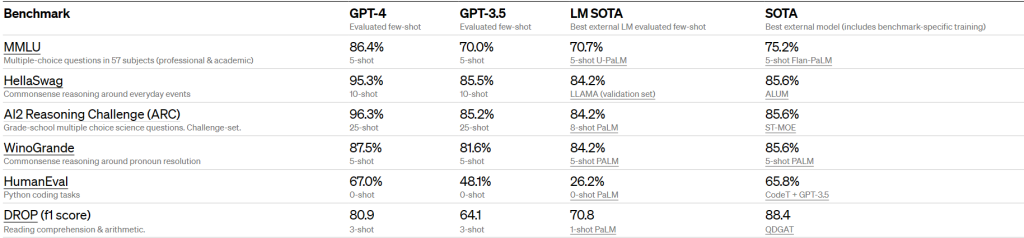
Si stima che le dimensioni del modello sarebbero aumentate dai 175 miliardi di parametri di GPT-3 a 1 trilione, ma queste voci sono state puntualmente smentite dal CEO di OpenAI Sam Altman (ne abbiamo parlato qui). Sicuramente, rispetto a ChatGPT e predecessori, GPT-4 esibisce delle migliorate capacità di ragionamento e problem solving e una maggiore accuratezza negli output, avendo ottenuto percentili approssimativi più alti tra i partecipanti ai test (che includevano circa 14mila domande di diverse materie e prese da esami universitari o professionali). Per fare un esempio, GPT-4 ha superato un esame di abilitazione alla professione forense simulato, ottenendo un punteggio che rientra nel primo 10% dei partecipanti al test (dove GPT-3.5 aveva ottenuto un punteggio nel 10% più basso).
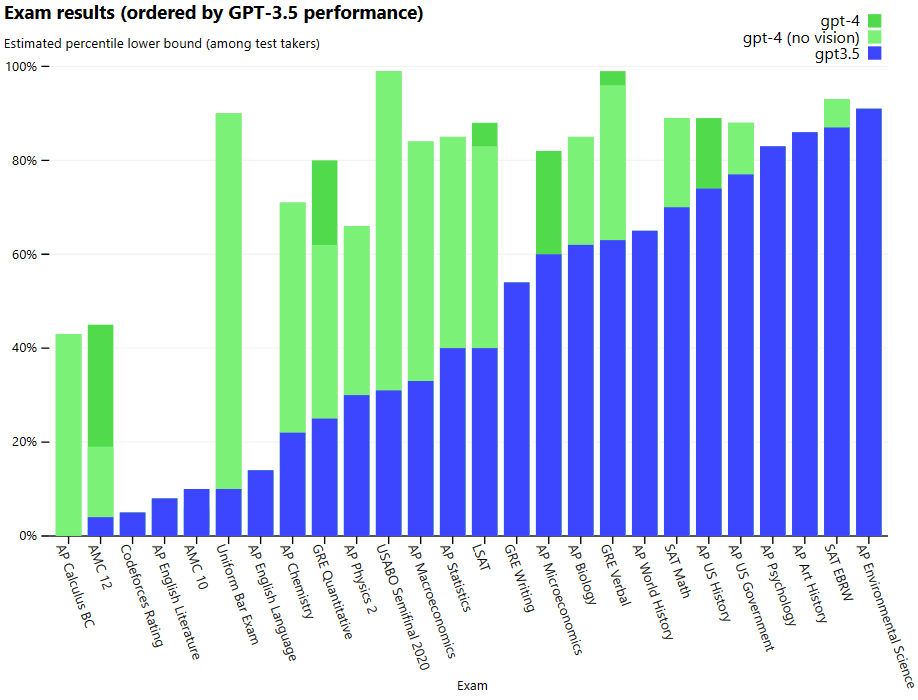


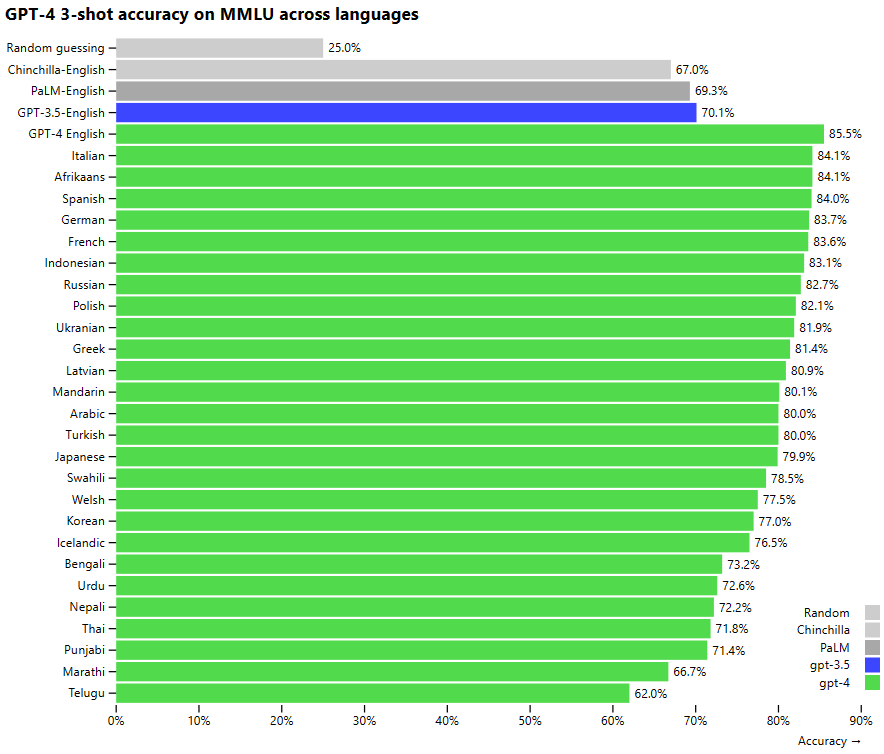
GPT-4 supera anche i precedenti modelli linguistici e la maggior parte dei sistemi allo stato dell’arte in una serie di benchmark NLP tradizionali, tra cui il MMLU (Multi-task language understanding), che copre 57 argomenti diversi in più lingue. Dopo l’inglese, la lingua in cui GPT-4 performa meglio nel MMLU (probabilmente anche debitore nei confronti di ChatGPT) è proprio l’italiano!
Dal paper rilasciato da OpenAI emerge che effettivamente GPT-4 sia decisamente più affidabile di GPT-3.5: il sistema è stato sottoposto a sei mesi di allineamento adversarial e formazione sulla sicurezza e nei test interni ha dimostrato di avere l’82% in meno di probabilità di rispondere a richieste di contenuti non consentiti e ha ridotto gli errori negli output del 40% rispetto a GPT-3.5. In sostanza, “in una conversazione casuale, la distinzione tra GPT-3.5 e GPT-4 può essere sottile. La differenza emerge quando aumenta la complessità della richiesta“, ha dichiarato OpenAI. “GPT-4 è più affidabile, creativo e in grado di gestire istruzioni molto più complesse rispetto a GPT-3.5“. Inoltre, GPT-4 aggiunge un’opzione di controllo di prompt e output che consente agli utenti di impostare un tono o uno stile specifico.
Al netto di questo, ovviamente, neanche GPT-4 è esente dai consueti bias e dal problema delle allucinazioni (ossia le risposte del tutto inventate, ma fornite con la stessa apparente autorità delle risposte corrette): ad esempio, alla richiesta di indirizzi di siti web che descrivessero le ultime ricerche sul cancro, a volte ha generato indirizzi internet che non esistevano. Fa sempre bene ricordare che i language model si limitano a manipolare testi in linguaggio naturale senza capirli veramente (le macchine non sono semantiche, ma solo sintattiche, benché l’NLP includa uno sviluppo della semantica in senso lato) e infatti i GPT producono testi sulla base di una massiccia elaborazione di tutti i contenuti web che possiedono e su cui sono addestrati. Tra questi, ci sono numerose fake news, contenuti tossici, spazzatura varia (cose che non possono venir discriminate senza una robusta attività di selezione e verifica delle fonti e che pertanto finiscono nel calderone degli output), cosa che continua a impedire a GPT-4 di essere usato come un surrogato di motore di ricerca (ne abbiamo parlato qui).
Questione diversa è ovviamente l’integrazione di ChatGPT (con GPT-4 di base) in Edge e Windows (di cui parleremo prossimamente), in cui c’è una vera e propria connessione al search engine per attingere alle informazioni mancanti da parte di Copilot: Microsoft ha infatti rivelato che il language model alla base dell’AI di Bing era già GPT-4 e il CTO di Microsoft Germania Andreas Braun ha rivelato alla rivista tedesca Heise che presto “avremo modelli multimodali che offriranno possibilità completamente diverse, ad esempio video. Microsoft è il principale investitore in OpenAI dopo aver pagato 10 miliardi di dollari per una partecipazione del 49% nell’azienda e ha integrato la tecnologia di OpenAI nel suo motore di ricerca Bing“. In ogni caso, l’unico modo veramente intelligente di usare GPT-3, ChatGPT o GPT-4, alla luce della loro relativa inaffidabilità rispetto alle fonti, è come tool di supporto, cioè farli lavorare con testi già scritti (parafrasi, manipolazioni, riassunti, rielaborazioni), fargli generare testi originali ma senza chiedere informazioni, o ancora tutte le altre funzioni come il coding.
GPT-4 e dove trovarlo
Attualmente GPT-4 è accessibile o tramite una waitlist lato API per gli sviluppatori o gli utenti più curiosi, o con ChatGPT Plus, l’abbonamento premium di ChatGPT dal costo di 20 dollari mensili, mentre la capacità di inserire immagini non è ancora accessibile direttamente al pubblico poiché limitata a un solo partner, la società Be my eyes, che ha creato un’app per aiutare persone non vedenti e ipovedenti. Per la release di GPT-4 OpenAI ha inoltre reso disponibile OpenAI Evals, il suo framework per la valutazione automatica delle prestazioni dei modelli AI e, oltre al consueto sodalizio di OpenAI con Microsoft, la compagnia di Altman ha annunciato di aver stretto accordi anche con altre aziende per integrare il GPT-4 nei loro prodotti, tra cui Duolingo, Stripe e Khan Academy.
Ora il futuro è più che mai aperto, ma dai benchmark e dai test sembra proprio che il salto dal 3 al 4 sia notevole (benché non rivoluzionario come molti dicono) ed è pacifico prevedere che avrà un impatto significativo (non diversamente da ChatGPT, ma meno esplosivo e più dipanato nel tempo). Quel che è certo è che, benché certe tecnologie fossero sul mercato da anni (come il Transformer, l’infrastruttura Azure, i large language model e le AI di Google e Microsoft), è grazie ad OpenAI che l’Intelligenza Artificiale è veramente arrivata al grande pubblico e che potremmo realmente essere entrati in quella fase di grande cambiamento che i PC vissero a partire dagli anni ’70 e le AI attendevano da anni. Questo cambierà drasticamente, nel bene e nel male, il volto del futuro: per ora stiamo seminando, ma tra non molto ci godremo anche il raccolto.
Leggi anche: