

Cos’è GPT-3, il modello linguistico su cui si basa ChatGPT, e perché è importante per l’Intelligenza Artificiale?
Da settimane non si parla d’altro: ChatGPT ha letteralmente “rotto il web” proprio in un momento di particolare fermento per l’AI e valicando presto, come sempre accade in questi casi, i confini della sua nicchia di interesse. Quindi leviamoci subito l’introduzione, per poi passare alla ciccia: ChatGPT è un Large Language Model (LLM) sviluppato da OpenAI e rilasciato il 30 novembre 2022, sostanzialmente la versione front-office, chatter bot e migliorata della rete neurale su cui si basa, GPT-3.
Ma per comprendere bene la portata di questo progetto, bisogna fare un veloce recap su alcune nozioni tecniche, perché il trucco è sempre dove non si guarda…
Transformer, deep learning e linguaggio naturale
Il campo dell’AI che tenta di implementare l’utilizzo del linguaggio naturale nelle Intelligenze Artificiali e che è considerato da alcuni anni estremamente promettente è il Natural Language Processing (NLP), mirato all’analisi, alla comprensione e alla generazione del linguaggio naturale e finalizzato alla raccolta di grandi masse di dati, alla catalogazione di file, al riconoscimento vocale, alla traduzione automatica e alla conversazione (conversational AI). Il NLP si fonda sulla teoria dei linguaggi formali e sulla linguistica computazionale e, incorporando la linguistica all’informatica, è sempre più capace di coniugare la complessità computazionale degli algoritmi di machine learning con la comprensione e l’elaborazione del linguaggio comunemente parlato dagli utenti umani. Un esempio di Intelligenze Artificiali conversazionali sono proprio i chatbot e gli assistenti vocali, un tipo di software automatici in grado di imitare il modo di parlare degli umani, simulare uno scambio dialogico e sostenere conversazioni “normali”. Questo ha portato, a partire dagli scorsi decenni, a famosi esperimenti come ELIZA, PARRY, Eugene Goostman, Replika, Microsoft Tay, e alla costruzione di reti neurali NLP ad uso interno per le aziende (noto è il caso recente di LaMDA, il chatbot di Google che si pensava senziente), oltre agli assistenti vocali comuni come Siri, Cortana, Google Assistant, Alexa, ecc.
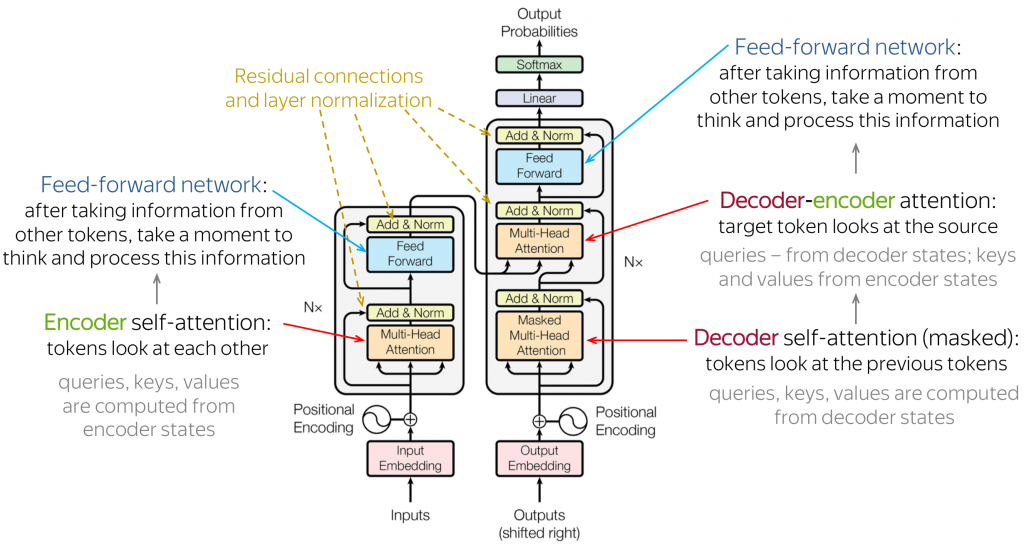
Una parte della ricerca e dello sviluppo in NLP si focalizza sui modelli linguistici generativi: massicce architetture neurali basate su modelli di machine learning che, addestrandosi su volumi di dati molto grossi, sono in grado di elaborare, estrarre, organizzare, collegare input testuali e restituire in output contenuti testuali o vocali in linguaggio naturale. Nel 2017 Google rilascia open-source il Transformer, un modello di deep learning progettato per gestire l’elaborazione del linguaggio naturale in modo più efficiente dello stato dell’arte (ad esempio modelli come l’LSTM). L’architettura Transformer, usata per la prima volta proprio sul modello NLP di Google BERT, è composta principalmente da un encoder, che prende in input una sequenza di parole trasformandola in una rappresentazione ad alta dimensionalità (su per giù un insieme di dati composti da tutte le parole inserite nel prompt e dai loro significati), e da un decoder, che assume in input la rappresentazione prodotta dall’encoder e la traduce in una sequenza di parole in output.
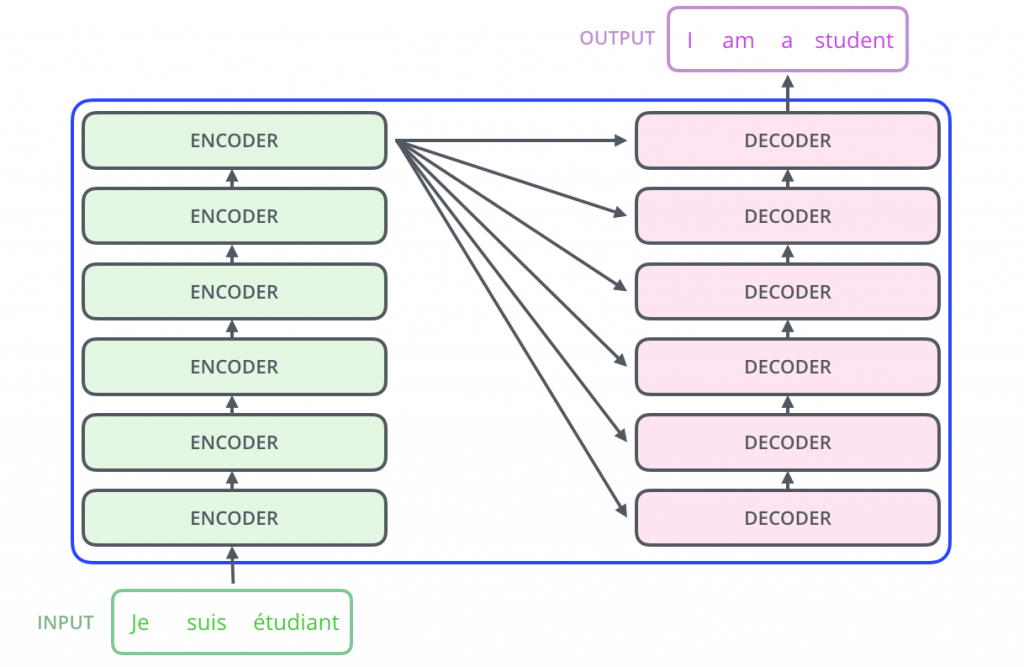
L’elaborazione della risposta in uscita è permessa da una serie di attention mechanism: nel machine learning l’attention è una tecnica di simulazione computazionale dell’attenzione umana e gli attention mechanism del Transformer gli consentono di processare il testo in modo parallelo. Questi meccanismi di attenzione assegnano un peso (un valore numerico, solitamente attribuito ai nodi di una rete neurale) ad ogni parola dell’input, in base all’importanza delle singole parole da un punto di vista semantico e sintattico: ad esempio, è più probabile che in una proposizione i sostantivi abbiano dei pesi maggior rispetto altri sintagmi (nella frase “la penna è sul tavolo” le parole essenziali, cioè senza le quali si perde ogni significato frasale, sono “penna” e “tavolo”, secondariamente il verbo “è” e la preposizione “sul” e infine l’articolo “la”). Addestrandosi su una grandissima quantità di dati, tra cui il riconoscimento delle parole, della prosodica e della sintassi, come di consueto, il modello ha potuto imparare a comprendere il contesto, collocarvi le informazioni e rispondere in maniera coerente alle richieste dell’utente.
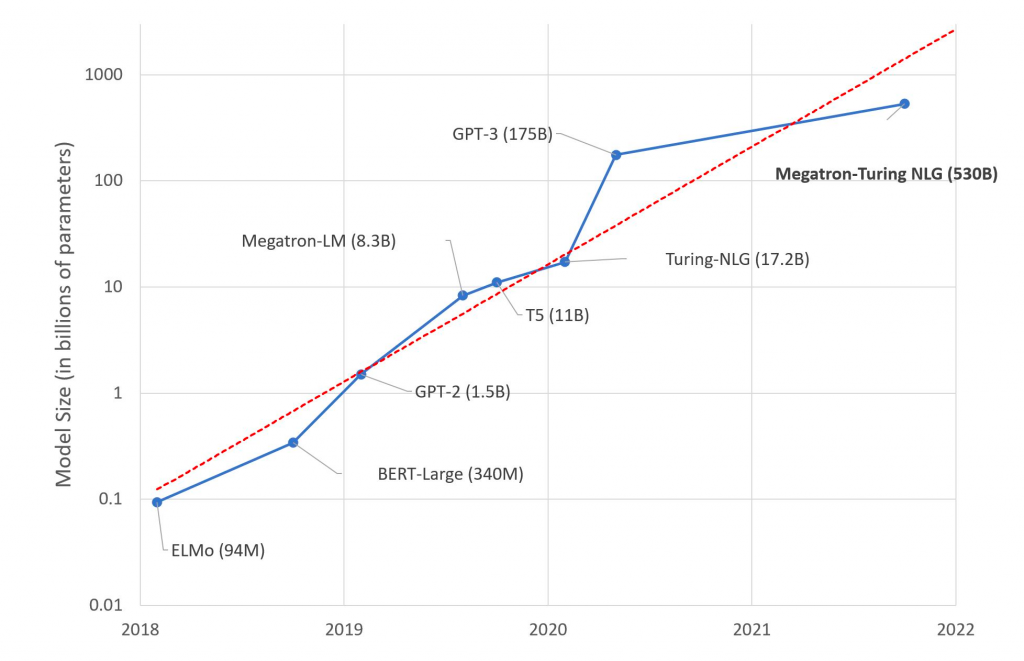
Nel febbraio 2020 Microsoft pubblica quello che all’epoca era definito come il “modello linguistico più grande mai pubblicato, con 17 miliardi di parametri“, il Turing Natural Language Generation (T-NLG). Ma tutto cambia quando, sempre nel 2020, OpenAI (un consorzio di aziende e privati per lo sviluppo di AI open source) annuncia che gli utenti potevano accedere alle API di GPT-3, la terza generazione dei modelli GPT-n (Generative Pre-trained Transformer), basata sull’architettura Transformer e finanziato da Microsoft con 1 miliardo di dollari di investimento e la condivisione dell’infrastruttura cloud Azure, che comprende migliaia di unità di elaborazione grafica A100 di Nvidia collegate tra loro e su cui i modelli sono stati “trainati”.
GPT-3, reti neurali e hybris
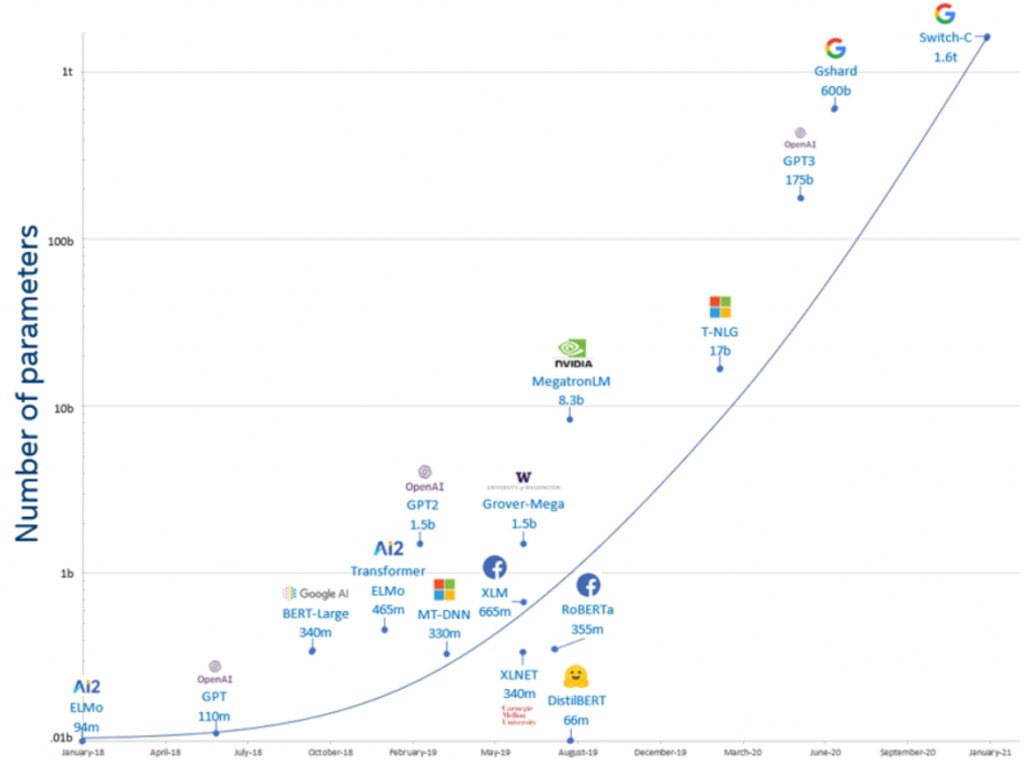
GPT-3 è il Large Language Model (LLM, modello linguistico di grandi dimensioni) alla base di ChatGPT e consiste in un set di strumenti di deep learning concepito per aiutare OpenAI a “esplorare i punti di forza e i limiti“ dell’architettura Transformer, attraverso un’interfaccia generica “text in, text out” in grado di svolgere quasi ogni tipo di compito in lingua inglese (e adesso multilingue). Più precisamente, GPT-3 è un modello linguistico autoregressivo e generativo (cioè genera testo a fronte di un prompt) basato su una rete di 96 decoder (rispetto all’architettura tipica dei Transformer, GPT-3 non implementa gli encoder). Tramite un processo di pre-allenamento generativo su masse di testo diversificato e non etichettato (unsupervised pre-training, con successiva discriminazione di ogni specifico task), GPT-3 prevede di volta in volta il prossimo token (nell’analisi lessicale, un token è la scomposizione di un’espressione linguistica, in questo caso all’incirca in parole), dimostrandosi rapido ed efficiente nel lavoro su file testuali. Questo pre-allenamento è stato eseguito su 300 miliardi di token e con 175 miliardi di parametri, ossia i pesi della rete (dei valori numerici attribuiti ai nodi), che vengono regolati, corretti e aggiustati durante l’addestramento dal continuo trial & error sulla base dei fallimenti e dei successi e che necessitano 800 GB di memoria per l’esecuzione.
Ciò ha permesso a GPT-3 di migliorare le prestazioni nella comprensione e nell’elaborazione del linguaggio naturale rispetto alle precedenti generazioni senza la necessità della supervisione umana, della validazione del training e della macchinosa etichettatura manuale. Al pre-addestramento, sono seguite una fase finale di fine-tuning, cioè un allenamento con esempi etichettati (supervised training con pochi esempi, siccome è in gran parte pre-trained), e l’utilizzo da parte umana (esperienza).

In generale, maggiore è il numero di parametri di un modello, maggiore è il numero di dati necessari per eseguire il training del modello (nel caso di GPT-3 esistono diverse versioni, ma la più grossa è proprio 175B). E non è un caso che esso sia probabilmente il migliore e più grande modello linguistico non-sparso sviluppato finora: la sua capacità è infatti di due ordini di grandezza superiore rispetto a GPT-2, nonostante GPT-3 sia strutturalmente simile ai suoi predecessori.


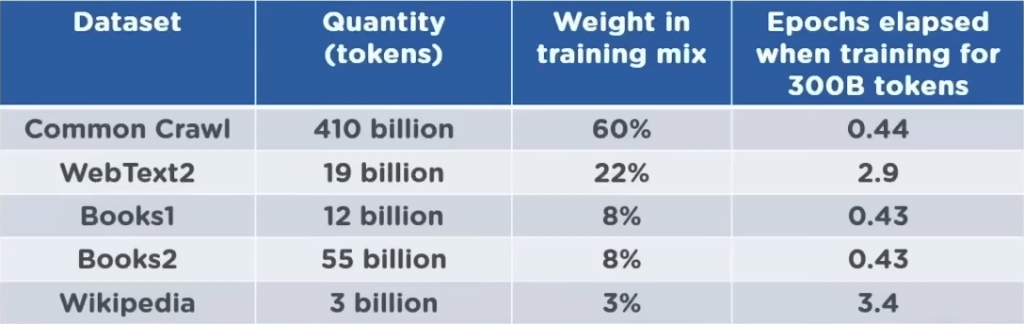
Con un’incredibile lunghezza del contesto (2048 token), 285.000 core di CPU, 10.000 GPU, circa 400 Gb/s di connettività di rete per ogni server GPU e 96 attention layers (ossia strati di decodifica), l’aumentata precisione di GPT-3 è dovuta alla maggiore capacità e al numero di parametri, tant’è che ammonta a circa dieci volte la capacità di T-NLG, il suo unico competitor fino al 2020. Inoltre, questo modello linguistico è pre-addestrato su oltre 45 TB di dati e centinaia di miliardi di parole, e il database di riferimento è gigantesco: nel training set di GPT-3 sono inclusi la Wikipedia inglese, Google Books e altri dataset molto corposi (TAB. 1).
La maggior parte delle informazioni (il 60%) proviene tuttavia dalla common knowledge di Internet resa disponibile da Common Crawl, un’organizzazione no-profit americana che effettua il crawling e lo scraping dei motori di ricerca, sondando i siti web per campionare le informazioni più rilevanti relative a determinate parole chiave. Common Crawl ha così memorizzato petabyte di dati (dati grezzi di pagine Web, estrazioni di metadati ed estratti di testo leggermente filtrati, complessivamente 3,1 miliardi di pagine per 420 terabyte di peso) in un archivio del web dal 2011 al 2021 (anno in cui GPT-3 è ferma anche come dataset), composto da 410 miliardi di token codificati a coppie di byte, diventando un conglomerato di articoli protetti da copyright, post su Internet, pagine Web e libri estratti da 60 milioni di domini in un periodo di circa 10 anni. Mentre una revisione del 2022 ha rilevato che l’addestramento continua includendo le revisioni di Wikipedia, uno dei problemi di Common Crawl è che, essendo un calderone di contenuti non selezionati, contiene sia informazioni vere che false, e infatti questo si ripercuote sul comportamento di GPT-3 e di ChatGPT, che non risultano pienamente affidabili (nonostante in buona parte lo siano) come fonti informative. Essendo inoltre stata trainata anche su Stack Overflow e vari tutorial di programmazione, GPT-3 può generare codice in formato CSS e JavaScript eXtension e in vari linguaggi di programmazione, tra cui ovviamente Python.
Secondo il teorema della scimmia instancabile, una scimmia che prema casualmente i tasti di una tastiera per un tempo infinito quasi certamente arriverà a comporre la Divina Commedia. Ecco, diciamo che il principio alla base di GPT-3 non è poi così diverso, considerando che ottimizza i tempi risparmiandosi tentativi infiniti: i dati immagazzinati per il pre-addestramento di GPT-3 sono infatti utilizzati dal modello per rintracciare le dipendenze statistiche tra le parole, codificate nei parametri della rete neurale, generando così testo semplicemente prevedendo le parole di volta in volta successive sulla base di queste correlazioni.
Per capire meglio, prendete il correttore automatico del vostro smartphone: scritta una parola, i suggerimenti che dà sono legati alla frequenza d’utilizzo delle parole suggerite e alla probabilità che vengano dopo la parola già scritta, in base alle serie storiche (cioè in base allo storico delle vostre immissioni di testo con quel device). I dati che possiede il correttore automatico del vostro telefono per lavorare sempre meglio sono solo i vostri, e neanche tutti, ma solo quelli necessari a prevedere una serie di parole in ordine decrescente di probabilità e comparsa. Ora immaginate che lo stesso meccanismo abbia improvvisamente miliardi di dati in più, diciamo tutto Internet: la cosa a cui state pensando è, su per giù, GPT-3, che così facendo va a costituire un robusto modello matematico-statistico del linguaggio e della conoscenza, capace di produrre discorsi di senso compiuto incasellando i token (parole e significati) per via meramente probabilistica.
Dato però che GPT-3 è un emulatore di linguaggio naturale non deterministico, ma probabilistico, risponderà sempre in modo leggermente diverso anche alle stesse domande. Per questo motivo è fondamentale settare la temperatura del modello, cioè il livello di randomizzazione: a temperatura zero, il modello fornisce sempre il token più probabile, ma all’aumentare della temperatura aumenta anche la casualità delle parole generate (cioè i token sono sempre più randomici), rendendo il contenuto sempre più improbabile e intraprendendo pathway sempre più “creativi”. Gli unici effetti collaterali, dovuti anche al training di GPT-3 su Common Crawl, sono che le informazioni potrebbero essere meno attendibili all’aumentare della stocastica del modello e che, a seconda di come vengono settati i prompt, il modello potrà fornire risposte anche a domande di cui non conosce la risposta (perché non è disponibile nulla in rete) semplicemente inventando e pescando i token più probabili.
Infine, GPT-3 può eseguire l’apprendimento zero shot (0S), few shot (FS) e one shot (1S), dove per shot si intende il numero di input utente necessari a un algoritmo prima di ottenere una risposta. In sostanza, dal momento che l’accuratezza del modello aumenta in funzione del numero dei parametri, l’accuratezza raggiunta tra 0 e 1 (pochi shot) da GPT-3 è sorprendente, e non serve né eseguire l’aggiornamento dei gradienti del modello (cioè metterlo a punto) né specializzarlo: basta interagire con esso tramite i suoi parametri, cioè chiedendo in linguaggio naturale un compito (0S) e fornendo un solo esempio (1S) o pochi esempi (FS) per avere almeno il 50% di probabilità che la risposta restituita in output sia corretta. Il modello, in pratica, si stabilizza da solo fino al 60% di precisione.
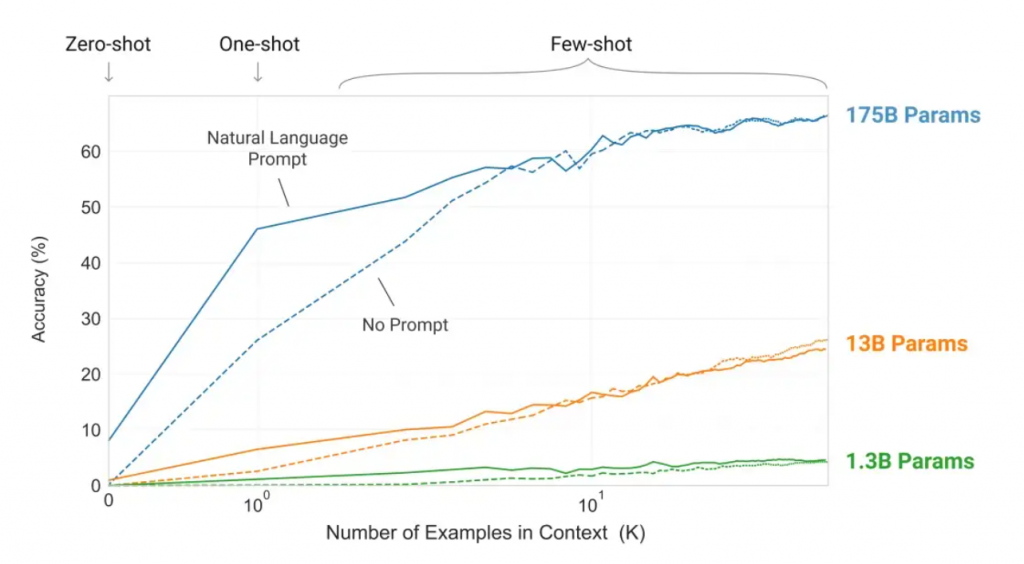

Testando GPT-3 sul dataset LAMBADA, che misura la capacità di un modello di prevedere l’ultima parola di frasi che richiedono la lettura di un paragrafo contestuale, emerge che nell’impostazione 0S (zero-shot) GPT-3 raggiunge il 76% su LAMBADA, un guadagno dell’8% rispetto al precedente stato dell’arte (SOTA, “State of the Art”). GPT-3 2.7B (una versione a 2,7 miliardi di parametri) supera il Turing-NLG 17B con impostazione FS (few-shot), e GPT-3 175B fa avanzare lo stato dell’arte del 18% (FIG. 1).
Testando invece GPT-3 sul dataset TriviaQA, si può osservare come le prestazioni crescano con le dimensioni e come le impostazioni 1S (one-shot) e FS (few-shot) battano 0S (zero-shot), superando lo stato dell’arte dell’odierno machine learning (FIG. 2).


GPT-3 esibisce prestazioni sorprendenti in molti campi come il riconoscimento del testo, la scrittura e il coding, ma anche la traduzione automatica: sebbene i suoi dati di addestramento fossero composti oltre il 90% da testo in inglese, includevano anche alcuni testi in lingua straniera (FIG. 3).
Scrivere come un umano, comprendere come un sasso: il senso comune
GPT-3 stupisce anche sul fronte del common sense reasoning. Nelle scienze cognitive, il senso comune è il background primigenio di credenze condivise che è alla base dell’intelligenza umana. Dal momento che l’Intelligenza Artificiale (di qualunque tipo essa sia, simbolica, probabilistica o neurale) rappresenta la conoscenza attraverso la logica formale (principalmente logica di primo ordine, ma anche fuzzy), incorporare il common sense reasoning nell’AI è sempre stato un obiettivo molto ambizioso, dato che per avere senso comune servirebbe una embodied cognition e una situated cognition (cioè avere esperienza del mondo attraverso una cognizione incarnata biologicamente e situata in un ambiente socio-culturale e naturale). Il ragionamento basato sul buon senso non è monotòno, contrariamente a quello basato sulla logica classica, e l’aggiunta di nuove informazioni fa decadere di volta in volta le inferenze avanzate precedentemente: se all’inizio pensi che la tua casa sia ancora integra e poi vedi in tv che un tornado ha spazzato via il tuo quartiere, abbandonerai la tua convinzione in favore di una nuova posizione. Nell’esempio più semplice e diffuso in campo AI, se affermo che Titti è un uccello, dedurrete che Titti può volare; ma specificando che Titti è un pinguino, l’inferenza risulta falsificata. La defeasible logic (traducibile in logica defettibile, un tipo di logica non-monotòna) include formalismi progettati per catturare i meccanismi alla base di questo tipo di esempi.
Non a caso proprio i modelli linguistici tendono a commettere errori soprattutto quando decifrare il linguaggio umano richiede la capacità di comprendere il senso comune, che un’AI difficilmente può incorporare, anche con gli adeguati training e set di dati in ingresso, poiché tali credenze inoggettivabili non possono venire computazionalmente formalizzate e simulate. Per fare un esempio, a maggio 2022 più di 400 ricercatori da 130 istituzioni hanno contribuito a una raccolta di oltre 200 compiti nota come Big-Bench (o Beyond the Imitation Game) la quale, oltre a test tradizionali per i modelli linguistici (come la comprensione del testo), comprendeva anche esercizi incentrati sul ragionamento logico e sul senso comune. I ricercatori del progetto Mosaic dell’Allen Institute for AI, che documenta le capacità di ragionamento basate sul senso comune dei modelli di Intelligenza Artificiale, hanno contribuito con un compito chiamato Social-IQa, consistente nel chiedere ad alcuni modelli linguistici di rispondere a domande che richiedono intelligenza sociale, come, ad esempio, “Jordan voleva dire a Tracy un segreto, quindi Jordan si è sporto verso Tracy. Perché lo ha fatto?”. I modelli linguistici di grandi dimensioni hanno ottenuto risultati del 20-30% meno accurati rispetto agli esseri umani. Ma era prima dell’avvento di GPT-3.
Per testare questo genere di prestazioni in GPT-3 è stato usato il dataset PhysicalQA (PIQA), che pone domande di buon senso su come funziona il mondo fisico e sonda il tipo di comprensione del mondo prodotta dalla macchina: GPT-3 raggiunge l’81,0% di precisione 0S, l’80.5% di precisione 1S e l’82.8% di precisione FS e ciò si confronta favorevolmente con l’accuratezza del 79,4% del precedente stato dell’arte di un RoBERTa messo a punto.

Altri risultati riguardano la comprensione della lettura, SuperGLUE, NLI, compiti sintetici e qualitativi come aritmetica, rimescolamento e manipolazione delle parole, analogie SAT, apprendimento e utilizzo di nuove parole, correzione della grammatica inglese, generazione di articoli di notizie. Proprio la generazione di articoli di news è tema di interesse: nel 2019, infatti, OpenAI sospese temporaneamente la public release di GPT-2 perché legittimamente preoccupata che il modello potesse generare notizie false. La cosa creò un precedente, date le politiche open source dell’azienda, ma alla fine OpenAI pubblicò una versione di GPT-2 depotenziata, circa l’8% delle dimensioni del modello originale.
Di contro, GPT-3 si è rivelato in grado di generare articoli di notizie praticamente indistinguibili da quelli reali da parte dei valutatori umani, tant’è che in un esperimento con la versione 175B gli 80 soggetti statunitensi messi alla prova con brevi articoli di 200 parole erano in grado di distinguere gli articoli falsi con solo il 52% di precisione (FIG. 4). Nel paper del 2020 in cui sono stati pubblicati questi risultati, i ricercatori hanno dettagliato le potenziali esternalità negative di di GPT-3, tra cui ancora una volta “disinformazione, spam, phishing, abuso di processi legali e governativi, scrittura di saggi accademici fraudolenti e scritti pretestuosi per l’ingegneria sociale“.
E infatti GPT-3 è diventata celebre proprio per un editoriale sul rapporto tra AI ed esseri umani da lei scritto e pubblicato sul The Guardian, in cui illustra i motivi per cui gli umani non dovrebbero temere la potenza dei deep neural networks: “Perché, ti potresti chiedere, gli esseri umani dovrebbero mettersi di proposito in pericolo? Non è forse l’essere umano la creatura più avanzata del pianeta? Perché dovrebbero pensare che qualcosa di inferiore, in un senso puramente oggettivo, potrebbe distruggerli?”. Nell’articolare delle risposte alle sue stesse domande, GPT-3 aveva, tra le tante, citato Matrix, esaminato le conseguenze della Rivoluzione industriale e analizzato l’etimologia del termine “robot” (“costretto a lavorare”).
Gli impressionanti risultati ottenuti da GPT-3 avevano nuovamente sollevato la possibilità che questi algoritmi stessero raggiungendo qualche effettiva forma di intelligenza. Ma per quanto un software capace di lavorare in questo modo possa sembrare intelligente, la realtà dei fatti è ben diversa: GPT-3, infatti, non solo aveva ricevuto un lungo addestramento specifico sul tema che avrebbe dovuto trattare, ma si era pure avvalso dell’ausilio di un redattore umano, che ha corretto formalmente, ortograficamente e strutturalmente le decine di versioni prodotte dall’AI sullo stesso argomento, selezionando le parti migliori e ottenendone una versione coerente e leggibile.
Gli stessi creatori di GPT-3 ammettono che il modello abbia notevoli punti deboli e commetta errori stupidi. In particolare, non funziona bene su compiti di sintesi del testo come ripetizioni, contraddizioni, perdita di coerenza su lunghi passaggi, non dissimilmente da altri modelli linguistici. L’architettura su cui è costruita, tra l’altro, rende GPT-3 più adatta per task basati sull’apprendimento contestuale, dal momento che si tratta di un modello di linguaggio autoregressivo e non bidirezionale (come BERT, il modello linguistico pre-addestrato di Google). De facto, come ogni macchina, GPT-3 non sa di cosa parla, sa solo come mettere in ordine le parole l’una dopo l’altra, perché crea delle dipendenze statistiche sulla base dei database a cui attinge per rifocillarsi di dati: in sostanza, il modello non ha conoscenza, è solo bravo a prevedere le parole successive nella sequenza, e non è nemmeno progettato per memorizzare o recuperare quanto prodotto nel corso della conversazione, che ripesca ogni volta appositamente.
Non solo: il neuroscienziato Gary Marcus, docente presso la New York University e fondatore di Robust.AI, aveva somministrato a GPT-3 una serie di semplici esercizi logici (di quelli che gli umani eseguono “ad occhi chiusi”) ottenendo spesso delle risposte assurde. Ad esempio, questi sono i risultati di accuratezza di GPT-3 su compiti aritmetici (FIG. 5): si evince dal grafico che i modelli più piccoli si comportano male su compiti semplici di aritmetica anche a una o due cifre e l’accuratezza sull’aritmetica a 4 cifre (e oltre) è bassa. Il motivo è semplice: GPT-3 è un modello linguistico, dunque non specializzato sul calcolo matematico, e può svolgere solo compiti legati al testo.

In un articolo su MIT Technology Review, Marcus aveva poi spiegato che “la comprensione del mondo di GPT-3 spesso è seriamente sbagliata, il che significa che non ci si può mai davvero fidare di ciò che dice“, aggiungendo che i sistemi come GPT-3 “non apprendono ciò che avviene nel mondo, ma imparano il modo in cui le persone usano le parole in relazione ad altre parole”. Il loro lavoro, in definitiva, è una sorta di massiccio copia-incolla statistico, in cui la macchina prevede quali parole hanno le maggiori probabilità di venire dopo le precedenti, di essere più o meno coerenti con quanto scritto prima, il tutto “senza avere alcuna idea di cosa stia facendo”.
Sta di fatto che proprio su una versione di GPT-3, GPT-3.5, si basa ChatGPT, che con la sua interfaccia utente e l’accessibilità pubblica mostra i miglioramenti apportati al modello GPT-3, la potenza e il livello raggiunto dai deep neural networks di OpenAI e uno scorcio sul futuro. Ma per comprendere meglio ChatGPT e le sue implicazioni, vi rimandiamo alla seconda parte di questa serie.
Leggi anche: