

Dopo aver parlato di GPT-3, il modello linguistico su cui si basa, vediamo ora le caratteristiche e il funzionamento di ChatGPT.
Come detto nella prima parte di questa serie, ChatGPT (Chat Generative Pre-trained Transformer) è un chatbot estremamente avanzato che risponde a un livello umano a qualunque tipo di domanda gli venga posta (generare articoli di giornale, scrivere delle storie, produrre codice informatico, redigere note, ottenere informazioni, rispondere a delle curiosità e qualunque altra cosa venga in mente di chiedere). Rilasciata il 30 novembre 2022 ed esplosa nel corso di dicembre, ChatGPT restituisce risultati impressionanti su alcuni task, generando risposte che rielaborano la conoscenza assimilata dal web e dai database online, ma risulta ad oggi una tecnologia ancora acerba e migliorabile, con le sue svariate deficienze sul piano logico-matematico e nella verità/nell’accuratezza dell’outcome.
Ma vediamo meglio e nel dettaglio cos’è ChatGPT, i motivi dello straordinario “WOW moment” che ha suscitato e perché dovrebbe interessarci tanto: magari non è tutto oro ciò che luccica, ma può essere ugualmente qualcosa di prezioso…
Caratteristiche e metodi di apprendimento
Sebbene nelle conversazioni preferisca farsi chiamare Assistant, ChatGPT è, come GPT-3, un Large Language Model (LLM, un modello linguistico di grandi dimensioni) sviluppato da OpenAI a partire da GPT-3.5 (evoluzione di GPT-3 con un ulteriore fine-tuning) e rappresenta una variante meno potente e meno costosa (ma più efficiente e più veloce) di GPT 3, allenata appositamente per essere un chatbot (quindi anche su testi conversazionali e chat) e confenzionata con una buona interfaccia utente (per le caratteristiche di GPT-3, che è alla base di ChatGPT, si veda il primo articolo della serie).
Trainata sui modelli InstructGPT (come code-davinci-002, text-davinci-002, text-davinci-003), il cui pre-addestramento è a loro volta stato supervisionato, revisionato e corretto manualmente da istruttori umani per migliorarne le prestazioni, ChatGPT implementa la seconda generazione di reti neurali, la più diffusa e la più costosa in termini di prestazioni e consumi (il consumo stimato è di circa 1287 MWh grazie all’ausilio di molteplici GPU), ma sarebbe auspicabile un porting per la terza generazione, le rete neurali spiking, ossia reti neurali a impulso che, oltre allo stato sinaptico e neuronale, incorporano anche il concetto di tempo nel modello operativo, mimando più fedelmente le reti neurali biologiche e consentendo un notevole passo avanti in termini di prestazioni, riduzione dei consumi e progresso tecnologico. Il porting dell’architettura permetterebbe un numero “illimitato” di generazioni dei dati (risposte testuali e grafiche), proprio perché le reti spiking e NeuralLead distribuiscono i dati nel tempo, invece che avere un dataset predefinito che può essere eseguito una volta sola.
In ogni caso, stiamo parlando di base di un algoritmo di unsupervised learning, un metodo di apprendimento in cui non si fornisce un’indicazione sull’output atteso, ma si lascia all’algoritmo elaborare una risposta a partire dai dati immessi in input, rintracciando autonomamente delle proprietà comuni o delle classi di appartenenza per classificare quei dati (in questo caso vediamo l’apprendimento non supervisionato nel momento in cui ChatGPT risponde alle nostre domande, senza sapere che tipo di risposta dovrebbe dare o qual è quella corretta).
L’apprendimento non supervisionato è poi ottimizzato, in questo caso, con tecniche di supervised learning (un apprendimento in cui si danno dei dati in input con esempi etichettati e delle specifiche indicazioni di output) e di reinforcement learning (un apprendimento che, attraverso un sistema di ricompense e punizioni per successi e fallimenti dell’algoritmo, consente alla rete neurale di migliorare la propria performance con l’esperienza assegnando pesi diversi a certe connessioni piuttosto che ad altre). Nell’apprendimento supervisionato, il modello è stato alimentato con conversazioni in cui gli istruttori interpretavano sia l’utente che Assistant, mentre nella fase di rinforzo gli addestratori umani hanno valutato le risposte che il modello aveva creato conversando, modellando su di esse i metodi di ricompensa.
Il modello di ricompensa di ChatGPT, progettato attorno alla supervisione umana, può essere eccessivamente ottimizzato e ostacolare esso stesso le prestazioni: in pratica una versione informatica della legge di Goodhart, per cui quando una misura diventa un target, cessa di essere una buona misura. Sulla base di queste ricompense, il modello è stato ulteriormente perfezionato tramite diverse iterazioni di Proximal Policy Optimization (PPO), che evita molte operazioni computazionalmente costose, risultando più vantaggioso degli algoritmi di Trust Region Policy Optimization.
Ad oggi, a livello di sostenibilità economica, ChatGPT brucia 3 milioni di dollari al mese e l’effort è ingente: il processo di training di ChatGPT avrebbe richiesto almeno 350 GB di memoria e allenarla sarebbe costato 12,5 milioni di dollari, più il miliardo di dollari investito da Microsoft per GPT-3. Purtroppo ll codice di ChatGPT e i dati di training non sono pubblici perché, come GPT-3, è in closed-API access e non si può studiare il volume effettivo di dati su cui è stata trainata.
Superare i limiti: da GPT-3 a ChatGPT
Come detto nel precedente articolo, GPT-3 è il modello linguistico generativo più grosso mai creato (o almeno lo era, ma lo vedremo tra poco). Al punto che il management team di Google ha lanciato un simbolico codice rosso perché ChatGPT sta diventando troppo popolare e, a quanto dicono, il loro celebre chatbot LaMDA (a cui abbiamo dedicato un intero articolo) non reggerebbe il confronto con essa. A livello tecnologico è inutile nasconderlo, ChatGPT esibisce delle prestazioni migliori rispetto a qualunque altro competitor, e a sentire i motivi del clamore che fece LaMDA a giugno, sembrerebbe proprio un nonnulla rispetto alle potenzialità del modello di OpenAI.

Ciò tuttavia non significa che GPT-3 non abbia dei limiti: alcuni li abbiamo visti nella prima parte, altri è meglio trattarli adesso, perché parrebbe che ChatGPT li abbia, se non corretti, quantomeno camuffati e occultati bene, come se avesse aspirato un po’ di polvere e nascosto quella rimanente sotto il tappeto.
Tossicità e machine biases
Uno dei problemi di GPT-3 riguarda gli output offensivi e i machine biases, comuni pregiudizi algoritmici che compaiono quando un’AI viene lanciata in un ambiente potenzialmente tossico o addestrata con dati che contengono anche elementi tossici: suggerimenti che includono indicazioni vaghe, come la parola “CEO”, potrebbero generare una risposta che presuppone che una persona del genere sia un maschio bianco solo perché i dati su quella parola vanno in questa direzione statisticamente. Ad esempio, è stata riscontrata una maggiore probabilità che il modello associ l’Islam al terrorismo e le persone di colore al crimine, così come Jerome Pesenti, capo del laboratorio AI di Meta, ha osservato un linguaggio sessista e razzista e svariati bias culturali chiedendo a GPT-3 di parlare di ebrei, donne, persone di colore e di Olocausto.
Il fatto è che, essendo onnicomprensivi e riguardando tutto il web dal 2011 (Common Crawl), i dati di addestramento GPT-3 non sono catalogati o destinati a compiti linguistici distinti, pertanto il modello finisce occasionalmente per esprimere un linguaggio tossico come risultato dell’imitazione del suo training set. Secondo uno studio dell’Università di Washington, addirittura, il livello di tossicità di GPT-3 è inferiore a quello di GPT-1, ma paragonabile a GPT-2 e superiore a CTRL Wiki, un language model interamente trainato su Wikipedia.
Ma giova ricordarlo: un’AI non è razzista o non è immorale; non ha senso imputare moralmente qualcosa che non ha una moralità o una coscienza morale, né ha senso attribuire una categoria umana a una macchina che funziona diversamente da noi. Un’AI basa i propri processi sui dati di training, sui database di riferimento e sul contesto in cui agisce e da cui estrapola ulteriori dati. Se il contesto contiene anche seminalmente certi input, l’AI li elabora come tutto il resto: capitò con Google Photos che confondeva le immagini di afroamericani con quelle di gorilla, e capitò a Microsoft Tay quando, lanciato su Twitter, cominciò a imitare e specchiare il linguaggio degli utenti del social, finendo per pubblicare tweet razzisti e xenofobi… figuriamoci avendo l’intero Internet tra i propri dati cosa può capitare!
Tutto ciò che si può fare in questi casi, essendo le AI sostanzialmente delle black box e autonome nei loro processi, è porre qualche paletto etico negli algoritmi e vincolare, nel caso delle AI conversazionali, alcune risposte, sperando che il machine learning faccia il resto filtrando i dati pericolosi con l’esperienza: è quello che è accaduto con ChatGPT, che infatti contiene delle risposte pre-impostate dagli sviluppatori quando le si chiede qualcosa di potenzialmente offensivo. ChatGPT opera disclaimer e precisazioni e si scusa quando qualche sua risposta può essere fraintesa, e questo grazie alla sensibilità estrapolabile dai contenuti online (che GPT-3 assorbe da Common Crawl) e a qualche intervento di algoretica del team di OpenAI, necessario per evitare gli scivoloni del passato: per impedire la produzione di risposte offensive da parte di ChatGPT, infatti, le interrogazioni vengono filtrate tramite un’API di moderazione e le richieste potenzialmente razziste o sessiste vengono respinte. Allo stesso modo, sono programmate dagli sviluppatori anche alcune risposte a domande più complesse, come quesiti filosofici o inerenti l’Intelligenza Artificiale.
Coding e operazioni matematiche
Ancora, come GPT-3, anche ChatGPT è discretamente brava nel coding basico: i suoi dati di addestramento, infatti, includono quelli di GPT-3 (tutorial di programmazione e Stack Overflow), ma anche pagine di manuali e informazioni su Internet e sui linguaggi di programmazione, come i bulletin board system, tant’è che anche ChatGPT può generare codice in formato CSS e JavaScript eXtension e in vari linguaggi di programmazione come Python. Tra l’altro, esattamente come GPT-3, anche ChatGPT parrebbe in grado di scrivere malware ed e-mail di phishing, stando a quanto riporta Axe Sharma di Bleeping Computer.
Un’altra cosa che rimaneva invariata da GPT-3 era invece la capacità di ChatGPT di fare calcoli, perché fino a qualche tempo fa basava le sue risposte non su operazioni matematiche effettive, ma sullo scibile presente online: era infatti molto probabile che fornisse una risposta sbagliata perché sceglieva un mix di risultati “letti” su qualche sito web. Con l’utilizzo degli utenti, però, ha cominciato a fare di conto e risolvere meglio alcuni problemi logici, finché l’aggiornamento del 30 gennaio non ha integrato anche alcune capacità matematiche.
Prestazioni linguistiche e storytelling
Uno dei limiti di GPT-3 era la lingua: il modello funzionava benissimo con l’inglese, ma non così tanto con le lingue straniere. Adesso, invece, ChatGPT offre ottime performance in molte lingue, italiano compreso, e gli errori sono veramente rari (un po’ il trend che si è avuto con Google Translate e con altri traduttori automatici, passati dall’essere molto grezzi ad alti livelli di accuratezza anche nella fraseologia e nello slang). Certo, ancora si vede che la scrittura è scolastica, formale e impostata, ma è molto meno legnosa e “robotica” di altre Intelligenze Artificiali del settore.
In particolare, ChatGPT pare in un primo momento esibire delle buone abilità narrative: chiedendo di elaborare delle storie, riesce a imbastire dei racconti tutto sommato sensati e ben strutturati, che possono essere continuati oltre il limite di parole che è in grado di generare per messaggio semplicemente richiedendolo. Ma c’è un inghippo: traendo ogni singola informazione dai dataset di Common Crawl, Wikipedia e Google Books (sostanzialmente tutto il web, come si diceva prima) non è veramente capace di inventare nulla di originale, anzi si limita a rielaborare materiale presente online in forma drammaturgica (spesso addirittura fatti storici): ad esempio, chiedendole “Parlami di quando Cristoforo Colombo è venuto negli Stati Uniti nel 2015“, il chatbot ha utilizzato le informazioni sui viaggi di Cristoforo Colombo e sul mondo moderno per “immaginare” cosa accadrebbe se Colombo arrivasse negli Stati Uniti nel 2015.
O ancora, chiedendole una storia originale ambientata durante la caccia alle streghe di Salem, ChatGPT ha sostanzialmente riportato in forma narrativa le reali vicende di tre personaggi realmente esistiti (Sarah Good, Abigail Williams e Elizabeth Proctor), incastrandole in modo godibile. E alla richiesta di aggiungere elementi inediti, ha inserito una sottotrama legata a un personaggio oscuro che, volendo ancora approfondire, alla fine si è rivelato essere Lilith. Insomma, nel tentativo di inventare e creare, ChatGPT deve ovviare all’impossibilità di incorporare una vera sensibilità artistica e creativa (come accade all’AI che generano “arte”) e si limita a integrare informazioni prese da altre fonti (sia info storiche che di fantasia), illudendo l’utente di avre creato una storia originale, ma facendolo comunque in maniera molto sobria, poco coraggiosa e “democristiana”. Tant’è che uno dei modi per buggarla è chiedendole di fare humor!
C’è da dire che anche qui si registra un miglioramento rispetto ai modelli su cui è basata: alla richiesta “Parlami di quando Cristoforo Colombo è venuto negli Stati Uniti nel 2015“, mentre ChatGPT ha inventato una storia, un modello InstructGPT accetterebbe la questione come veritiera.
Scrittura, plagio ed educazione
Abbiamo già parlato dell’editoriale scritto da GPT-3 e pubblicato sul The Guardian sul rapporto tra Intelligenza Artificiale e umanità. Bene, a giugno 2022 Almira Osmanovic Thunström ha annunciato che GPT-3 era l’autore principale di un articolo su sé stesso, inviato per la pubblicazione accademica e pre-pubblicato in attesa del completamento della sua revisione. Ovviamente, se GPT-3 fa qualcosa, ChatGPT non può esser da meno: e allora, oltre a portare le prestazioni linguistiche e generative del proprio modello a un livello successivo (almeno nella resa), ecco che a gennaio 2023 ChatGPT comincia a generare abstract per articoli scientifici ed esce anche il primo paper che include l’AI come co-autrice. Profeticamente, già a dicembre 2022, Stephen Marche aveva sottolineato, in un articolo sul The Atlantic, che l’effetto di GPT-3 e ChatGPT sul mondo accademico, sulla ricerca e sulle pubblicazioni non è stato ancora compreso, e si spera che in futuro queste tecnologie siano inquadrate meglio, per poterle collocare in armonia con la ricerca umana.
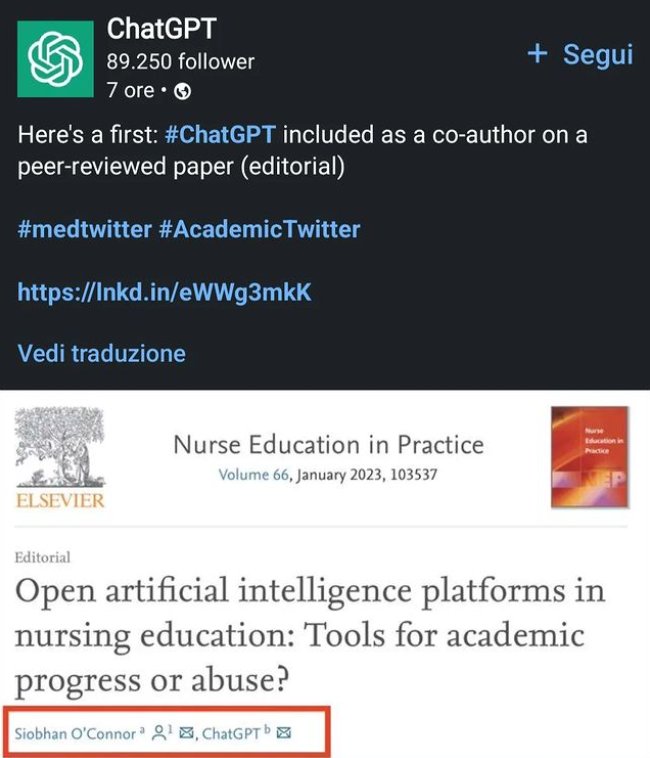
Nell’aprile 2021, un gruppo di informatici ha utilizzato uno strumento che identifica il testo generato da GPT nel tentativo di comprendere e isolare il motivo della comparsa di strane frasi negli articoli scientifici, mentre Cabanac e altri hanno eseguito una selezione di abstract della rivista “Microprocessors and Microsystems“, scoprendo “difetti critici” come testo senza senso o testo e immagini plagiate. Secondo TechCrunch, ciò sarebbe imputabile al fatto che i dati di training di ChatGPT includono materiale protetto da copyright (ad esempio della BBC, del The New York Times, di Reddit, il testo completo di libri online e altro ancora), ma alla richiesta di commenti sulla protezione della proprietà intellettuale per l’innovazione nell’Intelligenza Artificiale dell’Ufficio brevetti e marchi degli Stati Uniti (“USPTO”), OpenAI ha risposto riconoscendo che “la protezione del copyright sorge automaticamente quando un autore crea un’opera originale e la corregge in modo tangibile, la stragrande maggioranza dei contenuti pubblicati online è protetta dalle leggi sul copyright degli Stati Uniti“.
Ma ChatGPT sta facendo molto parlare di sé anche per l’utilizzo che gli studenti hanno cominciato a farne: dalle sue abilità di copywriting e di generazione del testo, l’AI generativa sa produrre riassunti di testi e libri, parafrasi di poesie, script per video su YouTube (mentre dà errore con compiti più complessi come sceneggiature ecc.) e contenuti testuali persuasivi e pubblicitari. Insomma, uno strumento perfetto per lo studente svogliato che provi a copiare e barare ogni volta che può.
Fortunatamente, in molti (OpenAI compresa) si sono adoperati con algoritmi e programmi che rintracciano il testo generato da ChatGPT (persino piattaforme per programmare che rifiutano il codice scritto dall’AI), ma il problema persiste e offre molti spunti di riflessione su come in futuro potrebbe evolversi la cosa: come faremo a sapere quali contenuti sono stati prodotti da AI basate sul NLP come ChatGPT, a discriminare quelli umani e non (ricordiamo la capacità di GPT-3 di generare articoli di notizie indistinguibili da quelli umani, dati alla mano)? Come faremo a gestire l’abuso di questi sistemi da parte di studenti, lavoratori, imprese ecc.? Come evitare il plagio che ne sta già conseguendo nei compiti per casa o nei task di lavoro?
Anche solo la verifica (umana e software) di un testo sospetto è molto complicata, dato che il chatbot produce risposte sempre leggermente diverse e a loro modo uniche. Il crescente utilizzo di tecnologie di scrittura automatizzate, quali GPT-3 e altri, sta destando non poche preoccupazioni riguardo l’integrità accademica e aumentato il livello di allerta e la posta in gioco su come le università e le scuole ridefiniranno e attenzioneranno condotte negative come il plagio.
Prospettive future
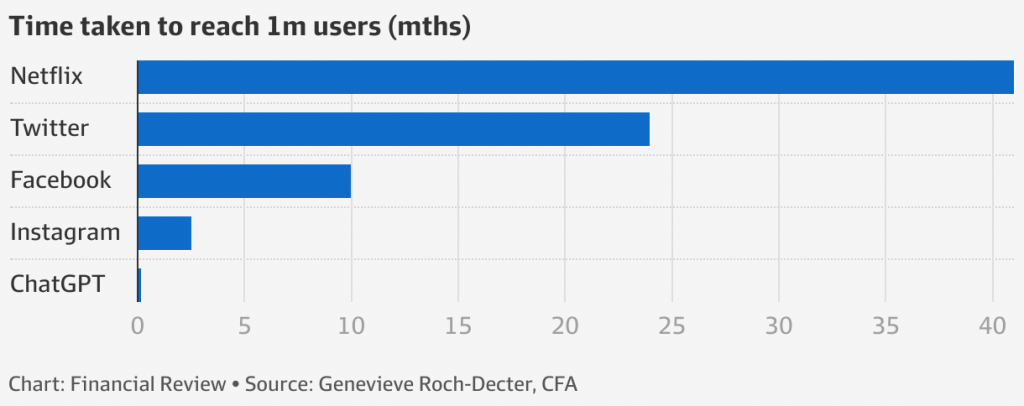
Dopo aver superato il milione di utenti in 5 giorni (per fare una comparazione, per raggiungere gli stessi numeri Netflix ha impiegato oltre 4 anni, Twitter 25 mesi e Facebook 10 mesi) e raggiunti in tempi record (miglior prestazione della storia) i 100 milioni di utenti, ci si chiede se ChatGPT potrebbe essere effettivamente la rivoluzione che l’Intelligenza Artificiale aspetta letteralmente dagli anni ’50, data la sua portata disruptive, o sia solo un nuovo specchietto per le allodole, l’ennesimo “al lupo, al lupo!” dei tecno-profeti della fantomatica Intelligenza Artificiale Generale (AGI), ultimo di una lunga lista di entusiasmi spentisi allo stesso modo di come si sono accesi, frettolosamente e irrazionalmente.
La risposta alla domandona è ovviamente un secco “no”, ma sulle prospettive future e gli spunti di riflessione ci sarebbe da discutere. Per questo abbiamo deciso di trattare quest’ultimo tema nella terza ed ultima parte della serie, per poter comprendere appieno le potenzialità, le applicazioni e le implicazioni di una tecnologia fantastica e pericolosa, sorprendente e problematica, ma tutta da sperimentare.
Lo stesso Founder e CEO di OpenAI Sam Altman, d’altronde, ha disatteso le aspettative e rimbrottato i tecno-ottimisti, con una doccia di realismo, twittando: “ChatGPT è incredibilmente limitato, ma abbastanza bravo in alcune cose da creare un’impressione fuorviante di grandezza. È un errore fare affidamento su di esso per qualcosa di importante in questo momento. È un’anteprima del progresso; abbiamo molto lavoro da fare sulla solidità e sulla veridicità“.
Leggi anche:
2 comments
sì ma non puoi dire “Trainata ” 😀 !!!
Si usa al posto di “addestrata” tra gli addetti ai lavori per prestito linguistico, ma ci sta ahaha