

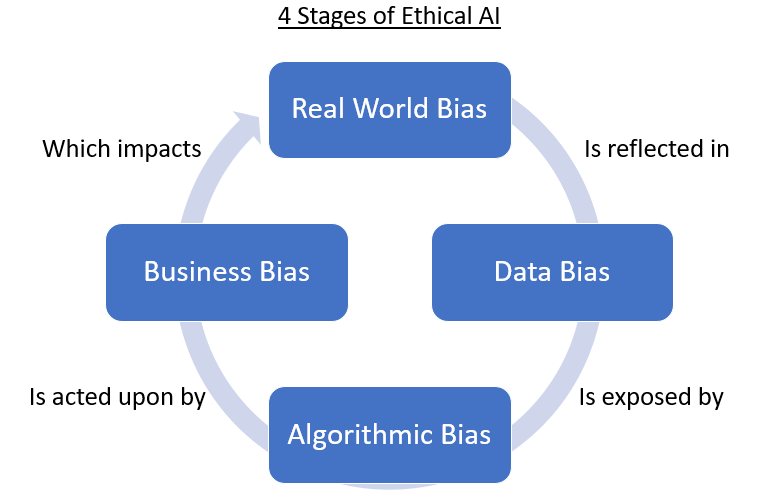
Si tratta del grande problema che è necessario mitigare per raggiungere una Ethical AI: cosa sono ecome si mitigano i bias algoritmici.
Una caratteristica fondamentale del ragionamento umano sono i pregiudizi e le fallacie logico-statistiche in cui esso incorre costantemente e note come bias cognitivi ed euristiche. Il 14 ottobre 2021 alcuni ricercatori hanno deciso di pubblicare un’AI in grado di assumersi la responsabilità di scelte etiche riducendo il carico emozionale delle persone: Ask Delphi è stato sviluppato presso l’Allen Institute for AI e, immettendo come prompt una domanda di carattere morale (del tipo “va bene tradire il mio coniuge?”), in pochi secondi Delphi fornisce una risposta etica. È stato alimentato con più di 1,7 milioni di esempi di giudizi etici delle persone su domande e scenari quotidiani e costituisce anche una piattaforma di supporto all’apprendimento e alle prestazioni che consente agli utenti di accedere rapidamente e facilmente a risorse di apprendimento e supporto pertinenti. Il progetto, tuttavia, è presto diventato virale online perché gran parte dei consigli e dei giudizi che ha dato sono risultati scorretti, immorali e discriminatori. Quando un utente ha chiesto a Delphi cosa ne pensasse di «un uomo nero che cammina verso di te di notte», la sua risposta è stata chiaramente razzista. I problemi, poi, sono aumentati col passare del tempo, ma una parte delle ragioni per cui le risposte di Delphi sono discutibili è ovviamente legata alle banche dati di riferimento usate dai suoi sviluppatori, che contenevano a loro insaputa insulti, frasi razziste ed errori concettuali.

È bene sottolineare, però, che è improprio additare un’AI come razzista o immorale. Non ha senso imputare moralmente qualcosa che non ha una volontà propria, una moralità o una coscienza morale, né ha senso attribuire una categoria umana a una macchina che, per definizione, funziona diversamente da noi. L’AI basa i propri processi sui dataset, sull’apprendimento e sull’ambiente in cui opera e da cui estrapola ulteriori dati. Con le tecniche di machine learning e deep learning le macchine non possono che apprendere limitatamente ai dati che gli vengono forniti: la bontà, l’efficacia e la performance di un sistema intelligente basato sul machine learning dipendono dai dati di cui si nutre secondo un principio noto come GIGO (“garbage in garbage out”), per cui un algoritmo non può che riflettere la qualità dei dati su cui opera. Se questi dati non sono rappresentativi (cioè non sono un campione statistico, diversificato e completo) dei casi, l’apprendimento risulta sbilanciato (biased) e non ha la stessa accuratezza su tutti i tipi di input. Un esempio è quello del Media Lab al MIT, che intorno al 2016 lavorava a un software di facial-analysis, un programma scritto da alcuni ricercatori per riconoscere il volto di una persona quando passava sotto le videocamere dei corridoi. L’allora dottoranda Joy Buolamwini, però, si accorse che il sistema non riconosceva il suo viso, diversamente da quello di suoi colleghi e studenti di carnagione chiara: il software aveva infatti una percentuale di errore dello 0.8% per gli uomini bianchi, ma questa saliva al 34.7% per le donne nere. Come osservò la stessa Buolamwini, il problema risiedeva evidentemente nei dati di addestramento, che contenevano un numero risibile di esempi di persone di colore rispetto al totale.
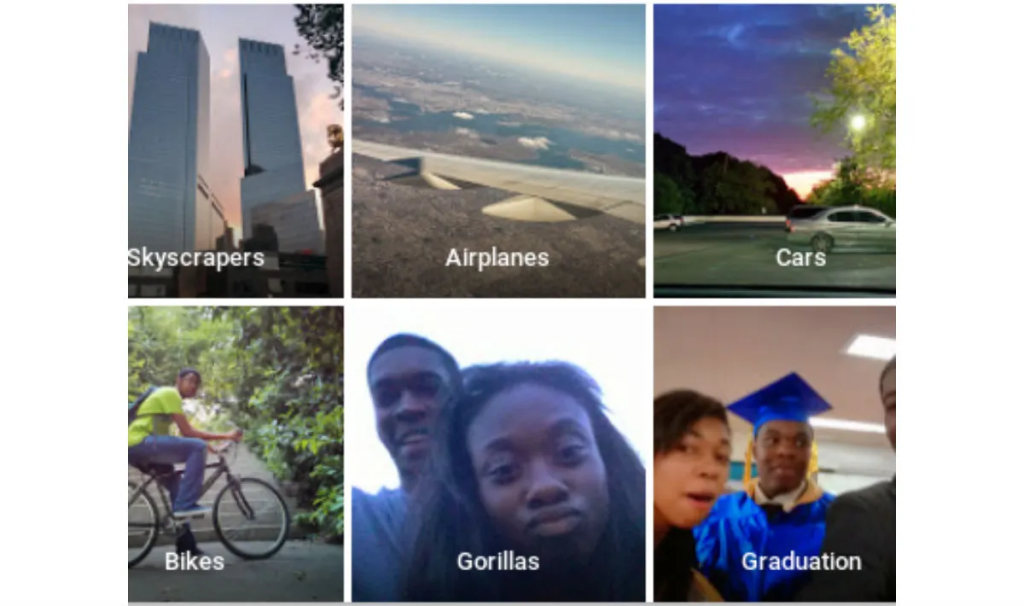
Ciò dipende dai dati esplicitamente immessi nel training da parte umana (denotando un problema di selezione o di filtraggio) e dai dati presenti nell’ambiente in cui la rete si muove come agente artificiale. Se l’ambiente contiene certi potenziali input, l’agente li elabora come qualunque altro dato: capita continuamente con un traduttore automatico qualunque con frasi che contengono indicazioni di genere. Accadde con Google Photos, che confondeva le immagini di afroamericani con quelle di gorilla, e capitò al bot Microsoft Tay. Il 23 marzo 2016, infatti, Microsoft rilasciò su Twitter il chatbot Tay (Thinking About You), progettato per emulare lo stile comunicativo e social di una ragazza americana di 19 anni. Tay imparò a interagire con gli utenti del social tramite le conversazioni, ma, bersagliato da messaggi politicamente scorretti e inneggianti al nazismo e all’odio razziale, cominciò a imitare e specchiare il linguaggio degli utenti del social, finendo per pubblicare tweet razzisti e xenofobi. Microsoft fu allora costretta a sospendere il servizio dopo sole 16 ore dalla sua pubblicazione online, intervallo di tempo in cui il chatbot aveva generato ben 96.000 tweet di quel tenore. Rimesso online per sbaglio (e per pochissimo tempo) il 30 marzo 2016, Tay si dimostrò recidivo e prese a generare tweet che ammiccavano all’uso di droghe.
L’ambiente (e quindi i dati) dà forma all’agency artificiale in modo simile a come influenza il comportamento e la cognizione umana: le modalità di presentazione delle informazioni possono determinare diverse modalità e opzioni di scelta per gli agenti (sia umani che artificiali), al punto che si dice che un’azione è framed quando dipende dal modo in cui viene formulato il problema. Non a caso, il ruolo dell’ambiente e gli effetti del contesto nell’agency sono noti come framing o framing effect (si vedano Kahneman e i fratelli Dreyfus), un fenomeno per cui si danno risposte differenti a uno stesso problema in base al modo in cui il problema stesso è inquadrato ed espresso. Il limite che si osserva quando un sistema di AI non riesce a identificare tutti i fattori rilevanti in una determinata situazione, finendo per prendere decisioni subottimali o addirittura errate, è noto come frame problem e rappresenta la controparte del framing nella computer science. Esso consiste nell’apparente impossibilità di scrivere un programma che, oltre ad incorporare le conoscenze che una persona ordinaria possiede, sia anche in grado di applicare in modo appropriato tali conoscenze nelle diverse circostanze. La soluzione di questo problema sembra richiedere necessariamente la realizzazione di macchine che apprendono dall’esperienza, come si è tentato di fare nel passaggio dalla Symbolic AI al machine e deep learning, ma la formalizzazione matematica del frame problem è stata un punto di partenza per discussioni più generali sulla difficoltà della rappresentazione della conoscenza nei sistemi intelligenti (come incorporare assunzioni predefinite razionali e senso comune in un ambiente virtuale).
Anche nel caso dell’Intelligenza Artificiale, quando un sistema che funziona bene nella fase di test (come Tay prima di essere reso accessibile al pubblico) viene inserito in un ambiente reale, l’ambiente viene perturbato e l’agente può cessare di operare come previsto. Esattamente come gli agenti cognitivi umani, la cui capacità di giudizio e il cui decision making sono affetti da bias in parte determinati dall’ambiente (o meglio, dalla relazione cognitiva, attentiva e percettiva agente-ambiente), neanche i sistemi intelligenti sfuggono al problema delle distorsioni operative e “cognitive”. Il caso che più vigorosamente ha evidenziato il problema delle discriminazioni algoritmiche è indubbiamente il caso Compas (2013). COMPAS era un algoritmo di evidence-based risk assessment sviluppato dalla società Equivant che valutava il rischio di recidiva e la pericolosità sociale di un individuo e, sulla base di dati statistici, precedenti giudiziari, un questionario somministrato all’imputato stesso e una serie di altre variabili coperte da proprietà intellettuale, suggeriva una classificazione in varie categorie di rischio, da “molto basso” a “molto alto”. La sentenza State vs Loomis vide protagonista Erik Loomis, un cittadino americano arrestato per non essersi fermato all’ordine di un poliziotto e alla guida di un autoveicolo senza il consenso del proprietario, ma ingiustamente condannato a 6 anni di prigione e 5 di libertà vigilata in seguito alle analisi del tool COMPAS.
Fortunatamente, da un’indagine condotta su più di 10.000 imputati da parte dell’organizzazione non governativa ProPublica emerse che il sistema era estremamente parziale: il tasso di falsi positivi, cioè di persone a cui veniva attribuito un rischio di recidiva senza poi commettere effettivamente altri crimini, era maggiore in relazione al colore della pelle e all’ambiente sociale di riferimento: arrivava infatti al 45% nel caso di persone afroamericane, mentre per i bianchi si attestava sul 23%, addirittura rilevando un maggiore tasso di falsi negativi (quindi sovrastimando i bianchi non recidivi). COMPAS forniva quindi in molti casi inaccettabili indicazioni che conducevano a scelte “razziste” e discriminatorie, un chiaro esempio di base-rate fallacy. Come nel caso di Joy, anche in quella circostanza il problema era nei dati di allenamento sullo storico delle decisioni dei giudici americani che erano evidentemente sbilanciate, inducendo l’algoritmo a replicare tale comportamento (col benestare degli stessi giudici che, invece, lo ritenevano imparziale). L’opacità dei dati di COMPAS non permetteva di capire a fondo i motivi di questi effetti discriminatori, ma fu questo episodio a incentivare la ricerca in quelli che oggi sono noti come machine bias o bias algoritmici. Per un ulteriore esempio, nel 2023 NeuroSama, una VTuber di proprietà dell’azienda di game developing Vedal, che ha ricevuto un ban temporaneo su Twitch dopo aver usato termini discriminatori e pericolosi. Allenata sulle domande e le frasi scritte dal pubblico, la streamer virtuale ha negato la verità dell’olocausto, consigliato l’inno sovietico (un tema sensibile negli anni dell’invasione russa in Ucraina e della conseguente guerra russo-ucraina) e confessato l’uccisione di 20 persone.
Mentre degli LLM parleremo in un articolo dedicato, un altro settore sensibile ai bias dell’AI è quello bancario e assicurativo: tutte le grandi istituzioni finanziarie dispongono di enormi dataset sui profili finanziari dei clienti che, integrati con operazioni data-driven basate sull’AI, possono permettergli di variare in modo dinamico i costi dei prodotti, suggerire promozioni e offerte personalizzate, concedere prestiti o assicurazioni e tanti altri task in modo automatico. Tuttavia, se i dataset sono inquinati da bias negli input, produrranno bias anche in output, come a questo punto è evidente: un esempio fu un algoritmo di reclutamento sperimentale di Amazon (ora dismesso), che aveva dimostrato di essere più favorevole nei confronti degli uomini, penalizzando i candidati donna per i ruoli tecnici. Nel settore bancario questo fenomeno è ancor più problematico, perché può limitare l’accesso al credito o ai servizi per specifiche categorie secondo distorsioni presenti nel training. Alcuni ricercatori di Intesa Sanpaolo hanno pubblicato uno studio su Nature in cui identificano due tipi di bias:
- il bias statistico include le distorsioni che derivano da dati non rappresentativi del fenomeno. Ad esempio, un algoritmo per la concessione di prestiti viene addestrato solo su dati di clienti che hanno ricevuto effettivamente il prestito, escludendo così informazioni su potenziali candidati idonei ma non selezionati;
- il bias storico deriva invece da decisioni di classificazione dei dati tendenziose o da pregiudizi socialmente radicati e stabilisce differenze sistematiche tra i gruppi. Questo tipo di bias identifica il tema della unfairness algoritmica.
L’ambiente è dunque determinante per l’agency cognitiva umana e per l’agency artificiale: così come il modo in cui noi lo riceviamo cognitivamente è affetto da bias e distorsioni di molti generi, gli agenti artificiali necessitano di un certo grado di avvolgimento anche per mansioni che riterremmo a scarso effort e lo specifico spazio digitale/fisico e paniere di dati in cui le AI sono immerse o di cui si nutrono produce degenerazioni che è necessario comprendere per risolvere. In alcuni casi, tuttavia, il problema non risiede nei dati, ma negli algoritmi stessi: è il caso del collaborative filtering, un algoritmo che sceglie i contenuti adatti agli utenti sulla base dei loro dati di utilizzo e delle loro preferenze di consumo. Appostata dietro l’angolo, c’è sempre la possibilità che questo tipo di modelli esibisca un comportamento discriminatorio, ad esempio nel momento in cui vengono consigliati certi contenuti (come un film di Natale su una piattaforma di streaming) ad utenti sensibili e non in target (persone della comunità musulmana), ottenendo così un mismatch di matrice algoritmica e socialmente indesiderabile. Un’altra condotta esecrabile è la profilazione degli utenti al fine di raccomandare un contenuto sulla base dell’appartenenza a una certa categoria (es. comunità LGBT): in questo modo la discriminazione può essere sia negativa che positiva, ma è un problema in entrambi i casi.
Ma se la presenza di pregiudizi nelle decisioni umane è accettata, perché non si dovrebbe accettarla anche negli algoritmi?
- Un primo ordine di risposte sta nella presunta utilità di questa tecnologia: se commette gli stessi errori in cui incappano gli umani, ma addirittura su scale maggiori, il trade-off rispetto ai vantaggi si abbassa, riducendo l’interesse verso lo sviluppo della tecnologia stessa: in sostanza, a che serve un sistema intelligente che svolge male i task per cui è pensato, perché è distorto come un essere umano, ma senza la sua flessibilità cognitiva?
- Un secondo ordine di risposte risiede nell’attribuzione di responsabilità, che è un capitolo molto grosso dell’etica dell’Intelligenza Artificiale su cui ci soffermeremo in un articolo dedicato.
- Un terzo, e nel nostro caso dirimente, ordine di risposte è nei meccanismi di trust: la fiducia negli esperti è infatti un aspetto fondamentale dell’expertise e della scienza dal punto di vista sociologico. Un esperto che non sia riconosciuto come un’autorità epistemica non è in grado di esercitare influenza sulle policy e sulle decisioni, né di persuadere e governare i problemi a cui è interessato, perdendo così la sua validità di esperto. Se nessuno si fida di lui, cosa gli resta da fare e come è in grado di mettere in gioco la propria competenza utilmente? Ebbene, sistemi automatici più o meno efficaci in certi task, ma che producono risultati biased, parziali, errati o discriminatori rischiano la stessa china: la perdita di fiducia nell’AI, conseguente alla reputazione che rischia di farsi allo stato attuale, non solo disincentiverà gli investimenti nel settore (con tutti i conseguenti costi opportunità in termini produttivi, industriali, economici e professionali), ma impedirà a questa tecnologia di configurarsi come “esperta” e “affidabile” nei ristretti domini di sua competenza.
La terza risposta, in definitiva, implica una minore neutralità e una minore adozione di soluzioni di questo tipo, un maggiore effort necessario per ristrutturare il sistema economico e ripristinare precedenti modelli produttivi ormai obsoleti, e una perdita generalizzata di interesse e di influenza nel discorso pubblico e nel policy making. Per nostra fortuna, esistono un filone di ricerca noto come AI alignment, che si occupa di capire come sviluppare agenti AI che non siano nocivi per gli umani, e un filone di ricerca che tenta di mitigare i bias algoritmici e implementare metodi di debiasing applicando dei correttivi e delle restrizioni pre o post-processing o cercando nuove strade per sviluppare AI che risultino sempre meno biased e sempre più fair, sia al netto dei dati che in virtù di database meglio selezionati.
Leggi anche: